Adding reverberation to musical sources is an essential part of creating an engaging listening experience. Since the earliest days of recording audio engineers have been developing methods to add reverb to their recordings. NeuralReverberator is a convolutional reverb synthesizer that uses an autoencoder as a generative model. The plug-in allows audio engineers to traverse the latent space of the autoencoder and generate different reverberation with varying timbre and duration. Check out the video below for a quick overview of the plug-in, how it works, and see it in action.

NeuralReverberator is open source -> check out the code on GitHub
macOS 10.10+
Windows build not yet available
Overview
NeuralReverberator is a VST2 plug-in built with the MATLAB Audio System Toolbox. An autoencoder was trained in Keras using normalized, log-power spectra of room impulse responses downsampled to 16 kHz.
After training the network, the decoder was used to generate log-power spectra for 2000 room impulse responses. This was achieved by navigating through the three dimensional latent space of the model. A left and right channel were generated for each step by slightly perturbing the latent space embedding of the left channel and then passing it through the decoder to generate the right channel.
Librosa was used to perform a transformation to audio samples that match the generated log-power spectra with the use of the Griffin-Lim algorithm. These .wav files were then loaded into a MATLAB struct and then could be loaded in the AudioPlugin class where these room impulses can be convolved with input audio in a DAW.
History
Reverberation has a long history in music, predating audio recording technologies. Music is shaped by the room in which it is performed and this drove the construction of cathedrals, performance halls, and other performance spaces. After audio recording technologies were introduced, faithfully capturing reverberation became the job of the audio engineer. Reverb chambers were built in recording studios to allow audio engineers to add in control reverberation after recording with loudspeakers and microphones placed in the chamber.
Having an entire room for adding reverberation to recordings was costly and this drove the development of spring and plate reverbs which offered reverberation-like effects in much smaller footprints. The EMT 140 plate reverberator (shown below) was highly influential and made its way on to many famous recordings.

When digital recording technologies were introduced advances in digital signal processing enabled new methods for applying artificial reverberation to recordings. Two major methods of doing so exist and are in use today. These are algorithmic and convolutional approaches.
Algorithmic approaches revolve around building a signal processing pipeline that applies transformations to the incoming audio in order to simulate sound traveling around an acoustic space. This usually involves summing a number of delayed and transformed copies of the input signal.
Convolutional approaches rely on capturing room impulse responses by playing an impulse over loudspeakers and recording the response of the room with microphones. Algorithmic approaches have the advantage of providing the user with semantic controls such as duration, diffusion, damping, etc. Convolutional approaches have the advantage of modeling real spaces with high accuracy, with the caveat that they do not provide the same level of parametric control as algorithmic approaches. NeuralReverberator combines aspects of both of these approaches by leveraging AI techniques, but under the hood operates as a convolutional reverberation processor.
Autoencoders
NeuralReverberator uses a deep autoencoder in order to learn compressed representations of room impulse responses. An autoencoder is composed of two parts. The encoder and the decoder. The encoder takes a high dimensional input and as it passes through the layers of the network the input is compressed to a much lower dimensionality. The output of the encoder is known as the code or latent representation. The decoder then takes as input the code and upsamples the input to produce an output with the same dimensionality as the original input. An autoencoder works by an unsupervised learning approach where the network is shown samples and the output of the decoder is compared with this input and back-propagation is used to update the weights of the network so the outputs of the decoder more closely match the input. To learn more about autoencoders I recommend watching this video from Arxiv Insights.
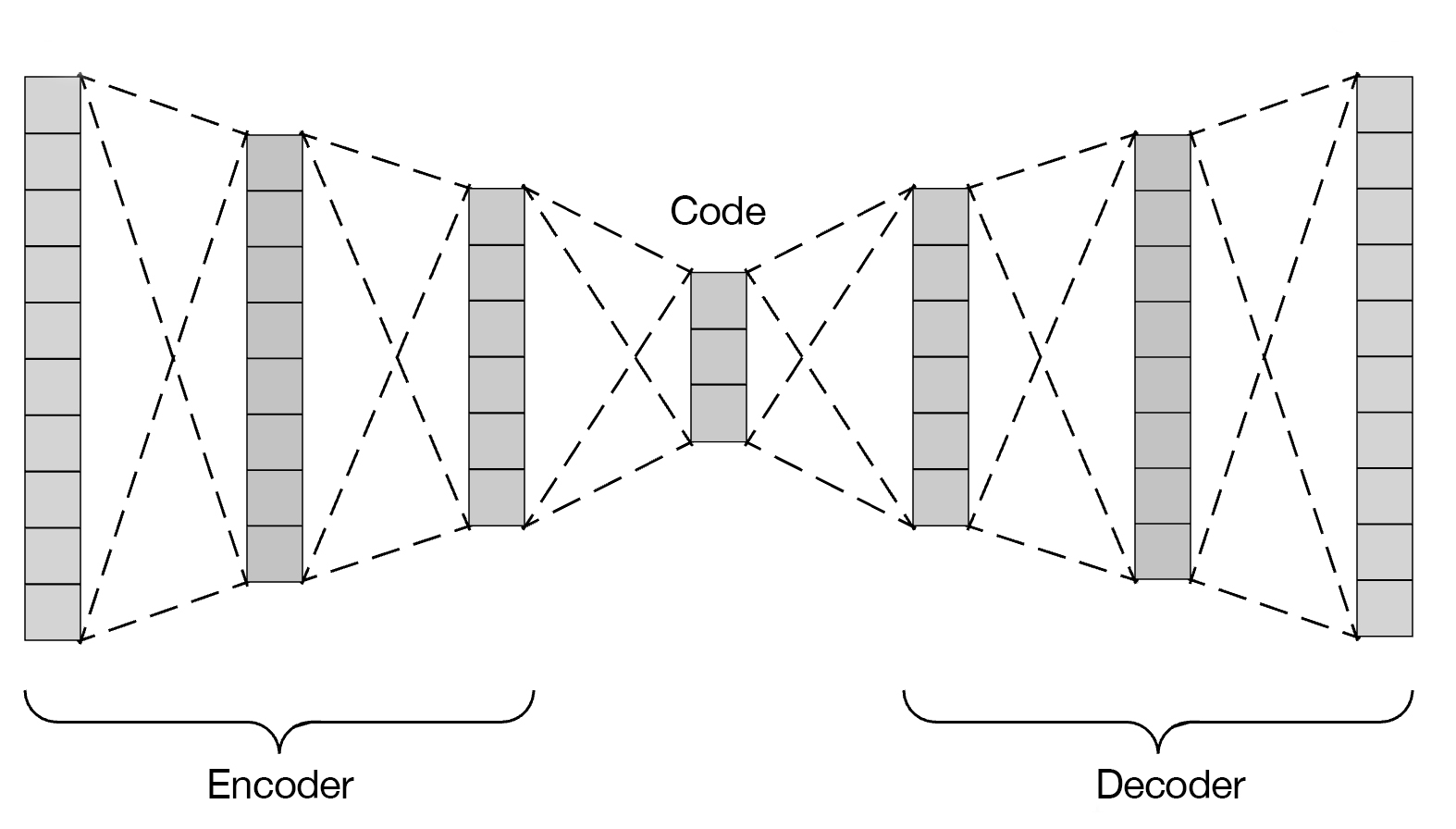
Model
The autoencoder used in this project is based upon the baseline autoencoder used in this paper from the Magenta project at Google Brain. Their paper outlines their method in the creation of the NSynth project, which allows for the synthesis of musical notes via a WaveNet autoencoder.
Their baseline model was chosen since it was simple enough to be implemented as proof of concept in Keras, and because it could be constructed in such a way to be compatible with the importKerasNetwork extension in MATLAB that allows for trained Keras networks to be loaded into MATLAB and used for inference. ( we will find out later that this wasn't important since DAGNetwork objects are supported for VST code generation ).
The spectral autoencoder takes as input a normalized, log power spectrogram of an impulse response. A small dataset of room impulse responses was created in order to train the network. It included ~1,500 multichannel samples. During training the multichannel samples were split into mono signals and fed to the autoencoder as separate impulse responses. The impulse responses were downsampled to 16 kHz, and truncated to ~2 seconds in order to decrease the dimensionality of the spectrograms. Librosa was used to create STFT log-power spectrograms from the downsampled impulse responses with a frame size of 1024 and hop size of 1/4.
The resultant spectrograms were then of shape (513, 128) and were fed into the model as images with a single channel. The encoder and decoder each consist of 10 convolutional layers followed by a leaky ReLU with alpha=0.1 and a batch normalization layer. The stride of each convolution in the encoder is set so as to downsample the image to achieve a 3 dimensional latent representation of the input. The decoder takes this latent vector as input and then uses transposed convolutions in order to upsample the code back to the original input size. The image below shows a sample from the dataset at the input of the encoder and then the reconstruction from the decoder on the right.

See the Keras code for specific details on the model used
The listening samples above show the input to the encoder on the left and the reconstructed time domain audio from the output spectrogram ( more on this in the following sections ). Note that there are some spectral artifacts but some of the quality of the impulse is similiar as we can see in the spectrogram shown in the image above. This example still leaves a lot to be desired but the autoencoder used here is quite simple and better results could be obtained by using a WaveNet model that can better model the long term characteristics of the reverberation decay.
Training
The model was trained for 300 epochs, which took around 1.5 hours on a NVIDIA Tesla V100 node of the Clemson University Palmetto Cluster. Convergence of the network was achieved very quickly at just over 100 epochs or less. The network was trained with the Adam optimizer with a learning rate of 0.0001 and a batch size of 8. Some experimentation was performed with different hyperparameters and modifications to the model such as increasing the number of filters in each convolutional layer as well as the size of the latent dimension, but these did not seem to effect the loss at convergence. Further experimentation with model architecture is likely to improve performance of the autoencoder but the results here are used a proof of concept. It is intended to implement a WaveNet autoencoder in the future as this model has shown superior performance and does not require reconstruction from spectrograms since it operates on time domain audio samples.


Generation
After some experimentation and a chat with some of the engineers at MATLAB, I discovered that the DAGNetwork object created by importing a trained Keras model into MATLAB was not currently supported for C/C++ code generation in the building of VST plug-ins. This meant that I could not perform inference in real-time from my model. Instead I decided to precompute impulse responses from the trained network and then use the sliders in the plug-in to allow the user to select the impulse responses and hear how they sound when convolved with incoming audio. This would have no affect on the user experience and would actually increase the efficiency of the plug-in ( at the cost of memory and disk space ).
As alluded to in the previous section, since the autoencoder operates on spectral representations, the output of the decoder must be transformed back into time domain audio in order to be used in the convolutional reverberation plug-in. To do this the Griffin-Lim algorithm was used. This algorithm allows for the estimation of the time domain signal from the STFT spectra at the output of the decoder. The latent code is three dimensional so 1000 points in the latent space were sampled at equal intervals from -2 to 2 in each dimension. This provides 1000 samples from the latent space for the user to explore. The Griffin-Lim algorithm was run for 1000 iterations for each sample. In addition the Width control ( explained in the next section ) gives the user even more possibilities.
In order to allow for stereo operation of the plug-in, ( since the model was trained to operate on mono impulse responses only ) at each step through the latent space, a second channel impulse response was generated by subtracting a small error vector from the latent vector with random values. These small perturbations are decoded as slightly different spectra but are closely related sonically. The output of the perturbed latent vectors can then be used for the right channel of the convolution and produce a convincing stereo effect.
You can download a set of 2000 impulse responses generated by the model here for free. You can use these in any DAW with a convolution plugin like Avid TL Space, Space Designer, Convolver, or Waves IR-L.
Plug-in
Training the network and generating outputs was only half of the project. In order to allow audio engineers to easily use these impulse responses, I built a VST plug-in in MATLAB using the VST generation capability of the Audio System Toolbox. It features a number of user-controllable parameters that gives audio engineers a powerful interface for synthesizing reverberation.

Plug-in running as MATLAB code in the audioTestBench.
The Input Gain control enables the user to control the level of the input signal before it is convolved with the selected impulse responses.
The x, y, and z, controls allow the user to sample room impulse responses from the latent space of the decoder. The values from 0-9 represent values of the three dimensions of the latent space from -2.0 to 2.0. When the user changes one of these slides an action is called that looks up the corresponding room impulse response and loads it for convolution.
This is coupled with the Width control which affects which room impulse response is loaded for the right channel. The left channel is always selected based upon the latent vector sliders, but a mono effect can be achieved by setting the Width to 0. With Width set to 1 then the correct 'stereo' room impulse response for the current left channel will be loaded for the right channel. In order to achieve more extreme stereo effects you can set the Width control to other values which will set the right channel to adjacent room impulse responses in the latent space. Greater Width will select room impulses responses that are further in the space.
Pre-delay, a common control found in reverberation plug-ins allows for the wet signal ( the signal that has been convolved with the impulse responses ) to be delayed in relation to the dry ( unprocessed ) signal. This has the effect of simulating a larger space with early reflections that take longer to reach the listener.
The plug-in features two filters that allows for additional control over shaping the timbre of the reverberation produced. The Highpass and Lowpass filters can be toggled on and off and also have a variable cutoff frequency control. These filters are implemented as second order bi-quad filters following the equations here.
The Mix control enables the dry signal to be mixed with the wet signal when using the plug-in as an insert. When using the plug-in on an effects return this control can be set to 100% so the output contains only the wet signal.
Finally, the Resampling control allows the user to disable impulse response resampling, which is enabled by default. As mentioned previously the network was trained on room impulse responses at 16 kHz sampling rate. In order for the quality of the room impulse response to be convolved correctly with incoming audio, both signals must be at the same sampling rate. When Resampling is enabled ( for sample rate 32 kHz, 44.1 kHz, 48 kHz, and 96 kHz ) the room impulse responses will be upsampled to the correct rate. This will preserve their pitch and duration. Optionally, the user can disable this behavior for experimental results. Since the un-resampled room impulse responses are at a low sample rate, if not upsampled, when convolved, will be high pitched and be shorter in duration.

Compiled plug-in running as C/C++ code in REAPER.
References + Acknowledgments
The inspiration for this project comes from NSynth, a project from Magenta, a research group within Google Brain.
Large portions of the dataset came from Open AIR Library, Greg Hopkins, C4DM, and many other sources.
MATLAB provided access to the Audio System Toolbox and DSP System Toolbox for the AES/MATLAB plug-in competition.
Award
This work won the Silver Award at the MATLAB Plugin Competition during the 145th Audio Engineering Society Convention in NYC.